I REGISTRI VOCALI: dalla concezione storica alla nozione dei meccanismi laringei
STORIA ED EVOLUZIONE DEL CONCETTO DI REGISTRO VOCALE
Il termine registro in riferimento alla voce è stato impiegato per la prima volta nel XIII secolo [i], adottato dalla terminologia relativa all’organistica [ii]. Fino al XIX secolo risultava assai difficile lo studio della fisiologia vocale, in quanto non esistevano molte delle tecnologie di cui disponiamo oggi. Essenzialmente le conoscenze di fisiologia fonatoria si basavano sullo studio della laringe tramite specchietti laringei (figura 1).
Uno dei primi studiosi ad analizzare con sguardo scientifico i registri vocali fu il celebre Manuel Garcia, il quale definì il registro vocale come segue: “attraverso la parola registro noi intendiamo una serie di toni consecutivi e omogenei che vanno dal più grave al più acuto, prodotti attraverso lo stesso principio meccanico, e la cui natura differisce essenzialmente da un’altra serie di toni ugualmente consecutivi e omogenei prodotti da un altro principio meccanico. Tutti i toni che appartengono allo stesso registro sono di conseguenza della stessa natura, a prescindere dalle variazioni di timbro e forza alle quali uno li sottoponga”[iii].
 |
| Figura 1. Manuel Garcia |
Garcia aveva descritto tre fondamentali registri: voce di petto, falsetto e voce di testa. Per ognuno di essi aveva identificato – per la voce maschile e per la voce femminile – un range frequenziale ben definito.
Nel 1884 gli autori Emil Behnke (chirurgo) e Leenox Browne (insegnante di canto) definirono similmente i registri come una serie di toni che vengono prodotti con lo stesso meccanismo. Descrissero un registro “spesso” (thick register), diviso a sua volta in lower-thick and upper-thick; un registro “sottile” (thin register) e – solo per le voci femminili – un registro “piccolo” (small register)[iv].
All’inizio del XX secolo buona parte degli insegnanti di canto e degli scienziati della voce concordava sul fatto che esistesse un numero di registri compreso tra 2 e 5. In questo periodo il termine meccanismo venne spesso usato come sinonimo di registro. Per esempio John Wilcox parlò di meccanismo pesante (heavy mechanism) e meccanismo leggero (light mechanism)[v].
Nel 1963 un gruppo di studio svedese pubblicò un lavoro di analisi della terminologia riguardante i registri vocali nei vari paesi europei. Gli autori raggrupparono i vari termini sotto 5 insiemi, che corrispondevano essenzialmente a strohbass, registro di petto, registro misto, voce di testa e fischio. Essi conclusero che l’unico sicuro comune denominatore dei registri era rappresentato dal range frequenziale su una scala musicale[vi].
Negli stessi anni iniziarono ad essere studiate le laringi escisse di cadavere e si riuscirono a riprodurre i registri e i passaggi di registro semplicemente variando la tensione muscolare e la pressione sottoglottica[vii].
Nel 1967 William Vennard descrisse per la prima volta nel libro Singing: The Mechanism and Technic la corrispondenza tra un determinato registro e reperti di imaging endoscopico laringeo. Egli mostrò che nel meccanismo pesante le corde vocali vibravano per tutta la lunghezza e a tutto spessore; nel meccanismo leggero vibravano solamente a livello del bordo libero e a volte non in tutta la lunghezza (figura 2, 3) [viii].
 |
| Figura 2. Meccanismo pesante [viii]. |
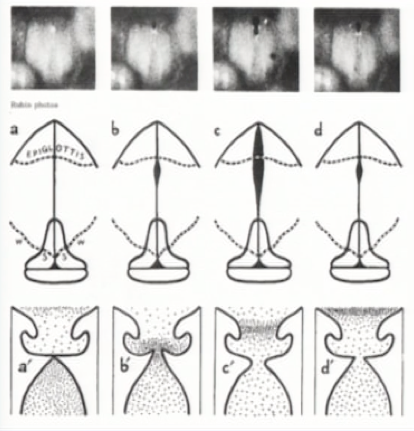 |
| Figura 3. Meccanismo leggero [viii]. |
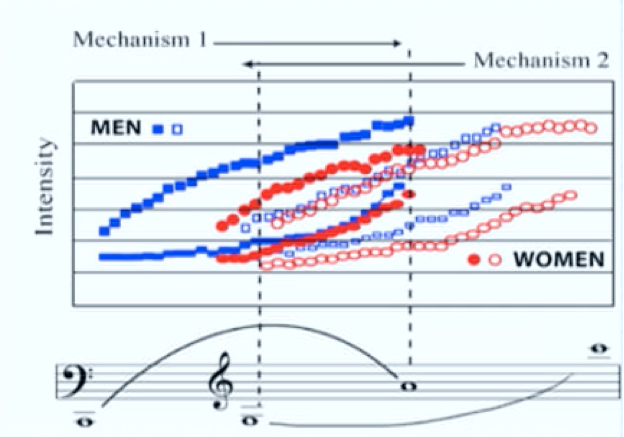
Nel 1970 il team di ricerca del chirurgo M. Hirano analizzò l’attività elettromiografica di una serie di muscoli (cricotiroideo, vocale e cricoaritenoideo laterale) durante l’emissione cantata, dimostrando una diversa attività muscolare a seconda del registro (figura 4) [ix].
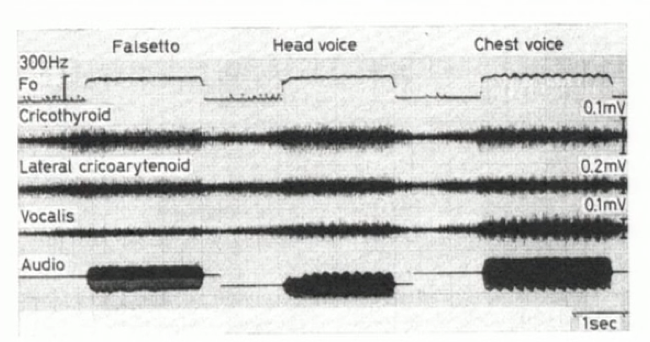 |
| Figura 4. Attività dei muscoli cricotiroideo, cricoaritenoideo laterale e vocale per diversi registri [ix]. |
Nel 1974 lo scienziato della voce H. Hollien pubblicò un articolo nel quale si proponeva una nuova definizione di registro vocale, considerato come una serie di frequenze emesse consecutivamente e aventi una qualità vocale praticamente identica [x]. Si affermava altresì che un registro vocale è da considerarsi un evento completamente laringeo. Hollien propose una nuova ed “incontaminata” terminologia per i registri vocali, che egli definì come:
- Pulse (strohbass, vocal fry)
- Modal (chest)
- Loft (head o falsetto)
- Flute (whistle).
Alla fine degli anni ’70 l’organizzazione medica internazionale Collegium Medicorum Theatri (CoMeT) fondò un Comitato Internazionale sui Registri Vocali con a capo il Dr. Hollien. Il comitato comprendeva più figure professionali tra cui otorinolaringoiatri, scienziati della voce e insegnanti di canto e aveva l’incarico di trovare una definizione univoce dei registri vocali da un punto di vista percettivo, fisiologico ed acustico. In una conferenza del 1983 tenutasi a Stoccolma [xi] il comitato arrivò ad una serie di conclusioni, qui presentate sinteticamente:
- I registri esistono e devono essere riconosciuti come entità.
- C’è una differenza in termini di registri tra voce parlata e voce cantata.
- Non si possono eliminare le differenze di registro da una voce umana ma si può imparare ad “addolcire” i passaggi di registro.
- La maggior parte dei membri del comitato fu d’accordo sul fatto che la sorgente dei registri probabilmente è rappresentata in parte dalla laringe e in parte dal vocal tract. Una minoranza del comitato ipotizzò invece che la sorgente dei registri vocali fosse esclusivamente laringea.
- Riguardo alla terminologia relativa ai registri, il comitato mise in discussione l’appropriatezza scientifica di termini come “voce di testa” e “voce di petto”. Queste storiche denominazioni prevedevano infatti l’identificazione del registro con le sensazioni vibratorie corporee del cantante. E’ vero che esistono sensazioni vibratorie di consonanza nella pratica del canto, ma esse non possono essere considerate come connotanti un determinato registro vocale. Le caratteristiche che definiscono un registro dovrebbero essere fenomeni di natura fisico-acustica (alla base delle sensazioni vibratorie di cui sopra). Il comitato concordò sul fatto che si doveva trovare una nuova terminologia per i registri, scevra dai retaggi etimologici del passato. Si suggerì di numerare i registri come segue: #1: il più grave dei registri (corrispondente al pulse, vocal fry etc.); #2: registro più usato nel parlato e nel cantato (modale, voce di petto, meccanismo pesante etc.); #3: registro acuto impiegato essenzialmente nel canto (falsetto, voce di testa, meccanismo leggero etc.) #4: registro molto acuto rilevato soprattutto nelle donne e nei bambini (fischio laringeo).
Nonostante gli sforzi della comunità scientifica vocologica per trovare un accordo, quello sui registri è rimasto a lungo un dibattito aperto. Infatti, ancora negli anni ’90, mentre alcuni autori definivano i registri basandosi sulle caratteristiche della qualità vocale: “Il termine registro è stato usato per descrivere percettivamente regioni distinte di qualità vocale che può essere mantenuta costante entro determinati range frequenziali e di intensità”[xii]; altri iniziavano a descriverli in base al meccanismo laringeo sottostante: “il registro vocale è un set o range di suoni in serie che risultano percettivamente simili e vengono prodotti da pattern vibratori cordali simili”[xiii].
Nel 2000 D. G. Miller definì due possibili approcci nella definizione dei registri, i quali possono essere considerati sia come entità di esclusiva pertinenza laringea, sia come entità derivanti non solo dalla sorgente, ma anche dall’attività del vocal tract.
Se si ripercorre schematicamente l’evoluzione della concezione di registro da Garcia a Miller, si apprezza che, nonostante gli sforzi, in quasi due secoli non si è raggiunto un reale consenso al riguardo.
 |
| Figura 5. l’evoluzione del concetto di registro dal 1840 al 2000. |
I MECCANISMI LARINGEI: LA RIVISITAZIONE DEL CONCETTO DI REGISTRO
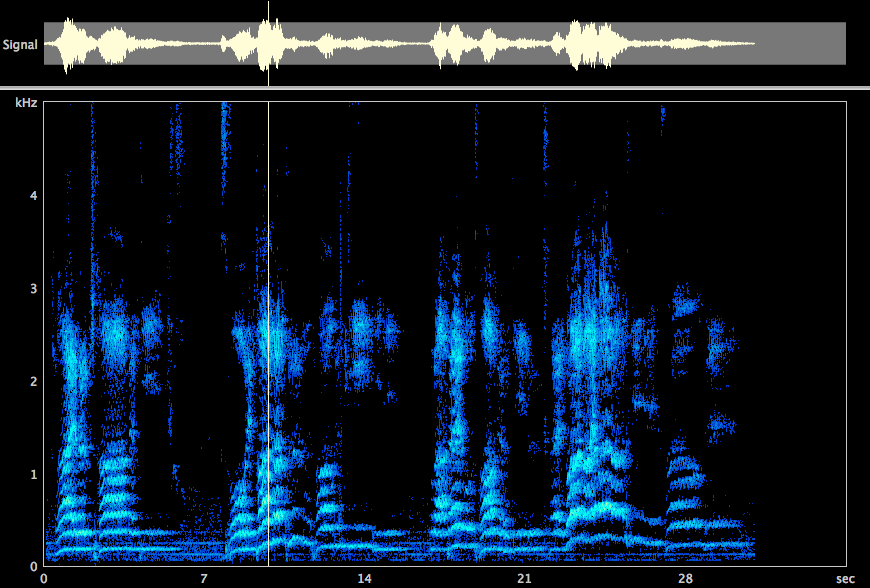
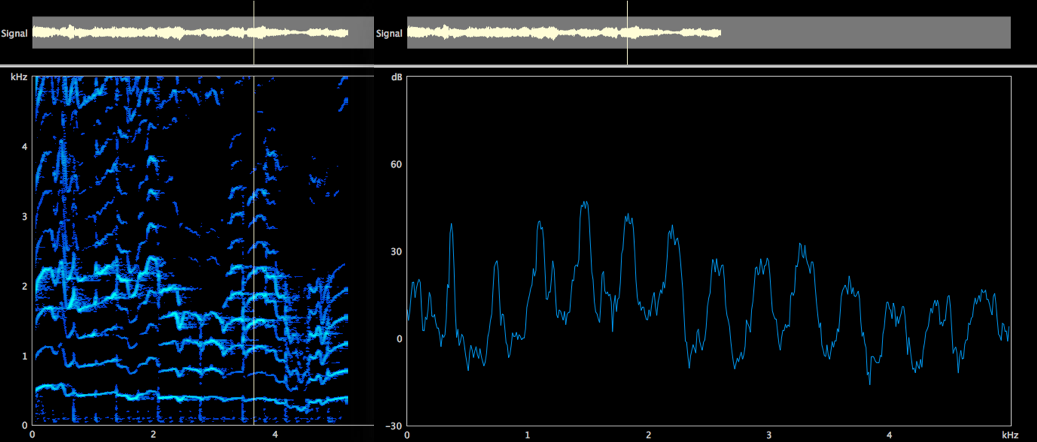
La ricerca scientifica nell’ambito dei registri vocali ha conosciuto una vera e propria svolta nel 2007 quando un gruppo di studio francese ha analizzato per la prima volta il fenomeno dei registri (e delle transizioni di registro) affiancando alle indagini acustiche ed endoscopiche, l’analisi elettroglottografica dell’attività della sorgente, dimostrando l’esistenza di 4 meccanismi vibratori laringei che sottostanno alle differenze percettive ricondotte storicamente ai registri vocali [xiv].
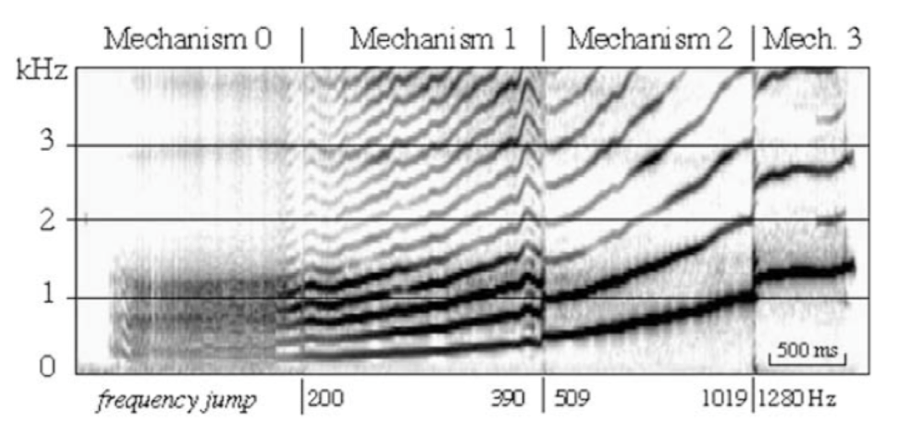 |
| Figura 6. spettrogramma di un glissando e relativi meccanismi laringei (da Roubeau et al.[xiv]) |
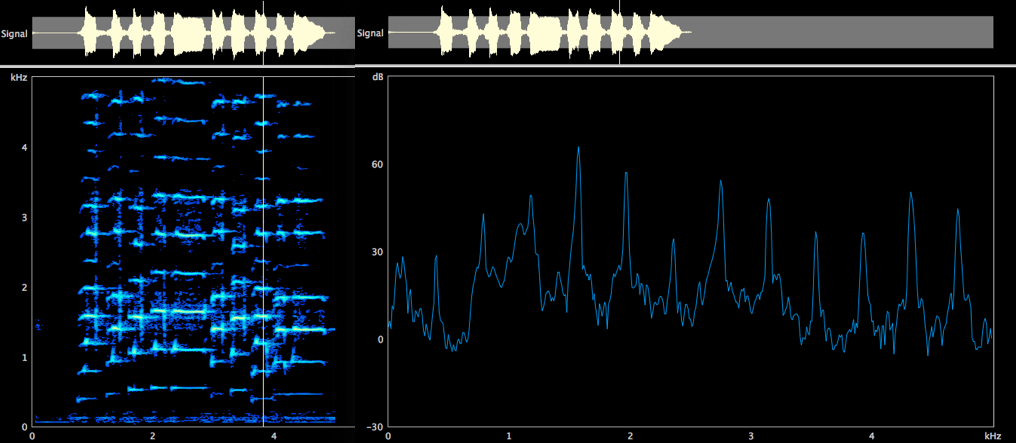
Analizzando il sonogramma di un glissando eseguito da un soprano senza porre attenzione all’estetica del suono, ma semplicemente muovendosi lentamente da un estremo all’altro dell’estensione vocale, si osserva che esistono quattro aree distinte, con caratteristiche spettrografiche diverse ed intervallate da punti di passaggio in corrispondenza dei quali si apprezzano “salti” frequenziali (figura 6). Il grande merito degli scienziati francesi è stato quello di dimostrare che le quattro aree poste in evidenza, oltre ad avere caratteristiche acustiche, endoscopiche e percettive differenti, corrispondono a pattern elettroglottografici caratteristici. Vale a dire che ad essi corrispondono i seguenti quattro meccanismi laringei vibratori:
Meccanismo 0 (M0): consente la produzione dei suoni più gravi nel range frequenziale. Esso si caratterizza endoscopicamente per avere le pliche vocali molto accorciate, spesse e lasse. All’EGG la fase di contatto risulta molto lunga rispetto al ciclo vibratorio cordale. I cicli vibratori cordali possono essere periodici a basse frequenze (intorno ai 70Hz), possono presentare periodicità multipla (coppie o triplette di cicli che si ripetono) oppure possono presentare impulsi glottici totalmente aperiodici (figura 7).
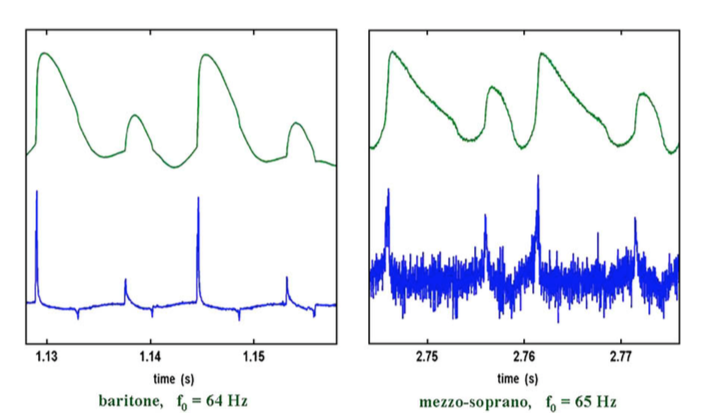 |
| Figura 7. Caratteristiche elettroglottografiche dell’M0 in un baritono e un mezzo soprano (da Roubeau et al.[xiv]) |
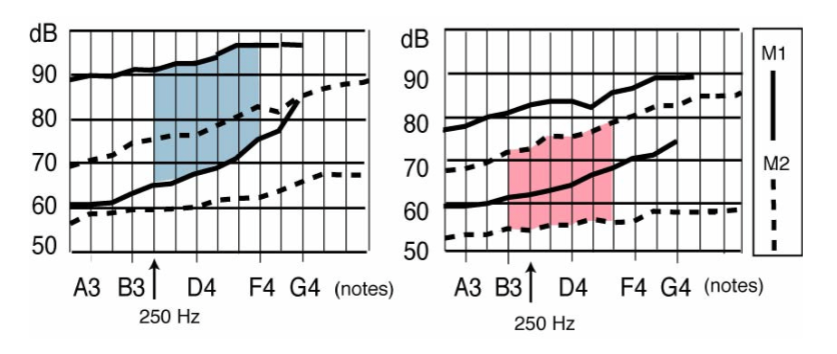
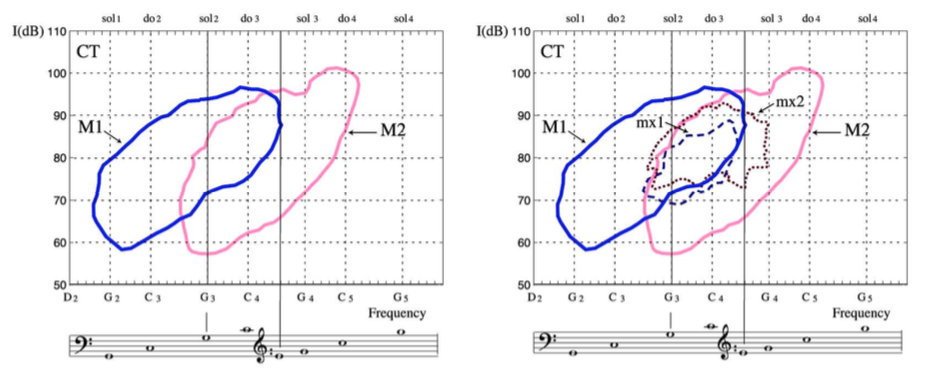
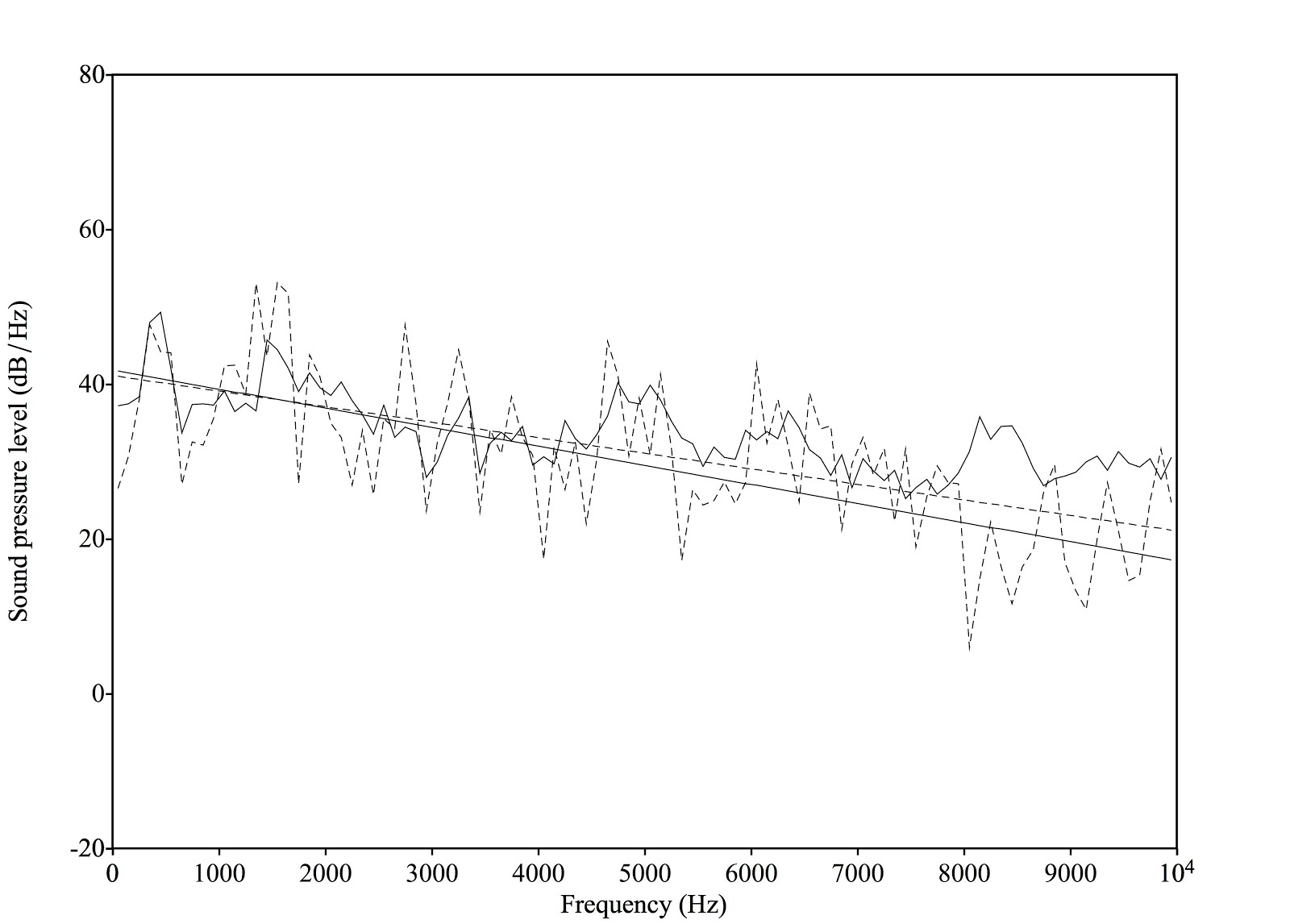
Meccanismo 1 (M1): è il meccanismo più utilizzato nella voce parlata, ma è molto impiegato anche nel canto, sia dai maschi che dalle femmine. Endoscopicamente si può apprezzare una vibrazione cordale a tutto spessore, alla quale partecipano anche gli strati tissutali profondi. All’EGG il segnale risulta macroscopicamente ampio e tipicamente asimmetrico. Il ciclo vibratorio glottico presenta una fase di chiusura brusca e ha un quoziente di apertura (definito come il rapporto tra la durata di apertura delle corde vocali rispetto alla durata dell’intero ciclo glottico) compreso tra 0.3 e 0.8. Nel meccanismo 1 il quoziente di apertura è influenzato dall’intensità del suono.
Meccanismo 2 (M2): in questo caso la corda non vibra a tutto spessore, ma solo nella componente più superficiale. Il segnale elettroglottografico risulta macroscopicamente meno ampio e più simmetrico rispetto a quello del meccanismo 1. Il quoziente di apertura è sempre maggiore di 0.5 ed è influenzato dalla frequenza fondamentale del suono. In generale, per suoni con la stessa frequenza, un M1 presenta quozienti di apertura minori rispetto ad un meccanismo 2. In altre parole, l’M1 prevede una fase di contatto cordale mediamente più lunga rispetto ad un M2 a parità di frequenza. Anche dal punto di vista spettrografico l’M2 differisce dall’M1 in quanto si caratterizza per una minore ricchezza armonica (figura 8-9).
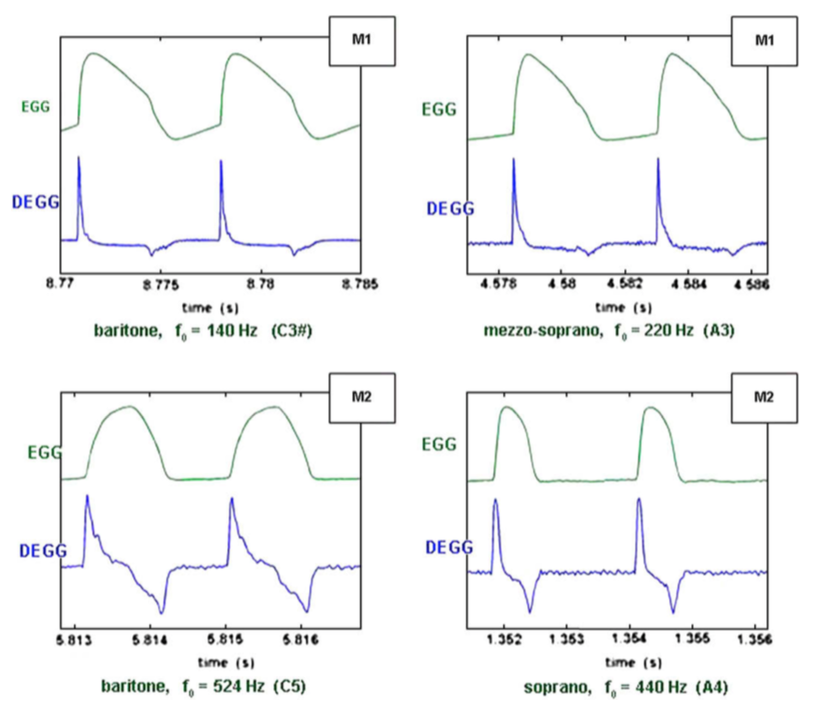 |
| Figura 8. Caratteristiche elettroglottografiche di M1 ed M2 (da Roubeau et al.[xiv]). |
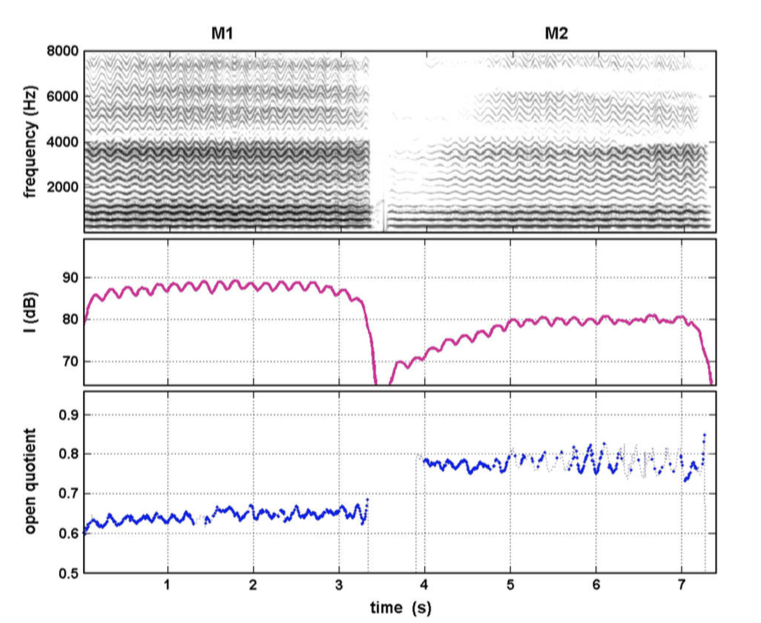 |
| Figura 9. Spettrogramma, intensità e quoziente di apertura di M1 ed M2 (da Roubeau et al.[xiv]) |
Meccanismo 3 (M3): è un meccanismo che consente di raggiungere frequenze anche molto elevate (1000-1400 Hz). Endoscopicamente le corde vocali sono estremamente tese e sottili. Spesso il contatto cordale manca e il suono viene emesso tramite un meccanismo “ad ancia”. Quando il contatto cordale – seppur minimo – è rilevabile, l’EGG mostra un segnale macroscopicamente molto simmetrico e di piccola ampiezza (analogo a quello dell’M2, vedi figura 10).
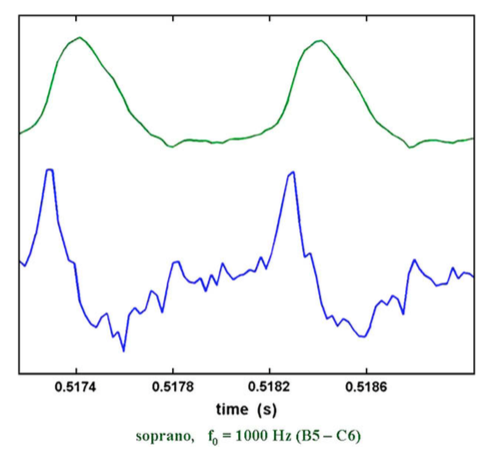 |
| Figura 10. Caratteristiche elettroglottografiche di M3 (da Roubeau et al.[xiv]) |
Il passaggio di registro è il punto critico in cui le corde acquisiscono improvvisamente un altro tipo di meccanismo vibratorio. Esso si accompagna – nella voce “non esperta” – ad un salto frequenziale che lo enfatizza. Questo fenomeno spesso non si verifica nei cantanti allenati, i quali sono in grado di mascherare abilmente il passaggio di registro. Parliamo di “mascheramento” del passaggio di registro perché di fatto esso esiste e non si può evitare: anche quando il performer addolcisce il passaggio di registro, le rilevazioni elettroglottografiche testimoniano che il passaggio avviene comunque (e avviene bruscamente).
Una conseguenza molto importante delle esposte evidenze scientifiche è rappresentata dalla ricaduta pratica che esse hanno in ambito terminologico. Oggi è possibile raggruppare la terminologia estremamente varia (e a volte confusa) relativa ai registri vocali al di sotto dei quattro meccanismi laringei descritti:
|
MECCANISMI |
||||
|
M0 |
M1 | M2 | M3 | |
| Nomenclatura storica dei registri |
Vocal fry
Pulse Strohbass |
Voce di petto
Chest voice Meccanismo pesante Modale |
Voce di testa
Head Voice Meccanismo leggero Falsetto |
Fischio laringeo Whistle Flageolet |
Sebbene alla luce delle nuove acquisizioni scientifiche i registri vocali propriamente detti possano essere considerati semplicemente in relazione all’attività della sorgente laringea, di fatto nel canto non si può non considerare la grande importanza che riveste il vocal tract nel determinare variazioni timbrico-risonanziali. Nuove prospettive nella comprensione del rapporto tra meccanismi vocali e variazioni risonanziali consisterà nello studio, tramite tecniche di imaging non invasive come la risonanza magnetica funzionale, del ruolo rivestito dal vocal tract nella voce cantata in relazione ai registri e alla miscela di essi, come avviene per esempio nel caso della cosiddetta voce mista, molto sfruttata in ambito artistico.
Articolo pubblicato in data 21.02.2016 – http://vocologicamente.blogspot.com
Bibliografia
[i] Duey, P. (1951). Bel Canto in Its Golden Age. New York: King’s Crown Press.
[ii] Merkel, C. (1863). Anatomie und Physiologie des menschlichen Stimm- und Sprachorgans. Leipzig: Abel.
[iii] Garcia M. (1840). Memoire sur la Voix Humaine. Parigi, Duverger.
[iv] Browne, L., & Behnke, E. (1884). Voice, Song, Speech. New York: Putnam.
[v] Wilcox, J. (1935). The Living Voice. New York: Carl Fischer.
[vi] Mörner, M., Fransesson, N., & Fant, G. (1964). Voice register terminology and standard pitch. Speech Transmission Laboratory Quarterly Status Progress Report, 4, 12-15.
[vii] Svec JG, Schutte HK, Miller DG. On pitch jumps between chest and falsetto registers in voice: data from living and excised human larynges. J Acoust Soc Am. 1999 Sep;106(3 Pt 1):1523-31.
[viii] Vennard, W. (1967). Singing: The Mechanism and Technic. New York: Carl Fischer.
[ix] Hirano, M., Vennard, W., & Ohala, J. (1970). Regulation of register, pitch, and intensity of voice: An electromyographic investigation of intrinsic laryngeal muscles. Folia Phoniatrica, 22, 1-20.
[x] Hollien, H. (1974). On vocal registers. Journal of Phonetics, 2,125-143.
[xi] Hollien, H. (1985). Report on vocal registers. Proceedings of the Stockholm Music Acoustics Conference, 1, 27-35.
[xii] Titze, IR. Principles of Voice Production, 1994.
[xiii] Sakakibara K-I. Production mechanism of vocie quality in singing. Journal of the Phonetic Society of Japan, 2003.
[xiv] Roubeau B, Henrich N, Castellengo M. Laryngeal vibratory mechanisms: the notion of vocal register revisited. J Voice. 2009 Jul;23(4):425-38.